Suppose for instance that you have one server in your company or business, and in that server there is an application and the server is connected to a data storage medium (such as disk array) which is storing your customer’s data such subscribe info, customer credit, or customer transaction history,…etc. the stored data is managed by the application living in our particular server. This is the typical environment of an online services provided by businesses and companies. What happens if that server fails in any level? Levels of failure might be in the server hardware itself, in the operating system, or in the application (the Application crashes).
If one of the above happens, the service will be offline until some correction or maintenance is done which may take long hours. For some businesses, if that happens, it will cost thousands or even millions of dollars and will cause endless trouble for your company or business. Here where High Availability comes in. Service availability is measured as a percentage of how much up-time is expected from the service during a period of time, if the service has 100% availability, that means the service never fail, and if, for example the service has 99% availability over a period of one year can have up to 3.65 days downtime or (1%) down time.
What achieves High Availability in the system?
The scenario as described above where we have single server providing the service is called “single point of failure” or “single node”. The single point of failure means the failure of one component in the infrastructure (server, switch, cable, application, etc) will cause the entire service to be interrupted. To make the system achieve High Availability, we must:
- Eliminate the single point of failure by providing redundancy.
- Providing a way to detect a failure and cutover the service to the redundant node when the serving node is down.
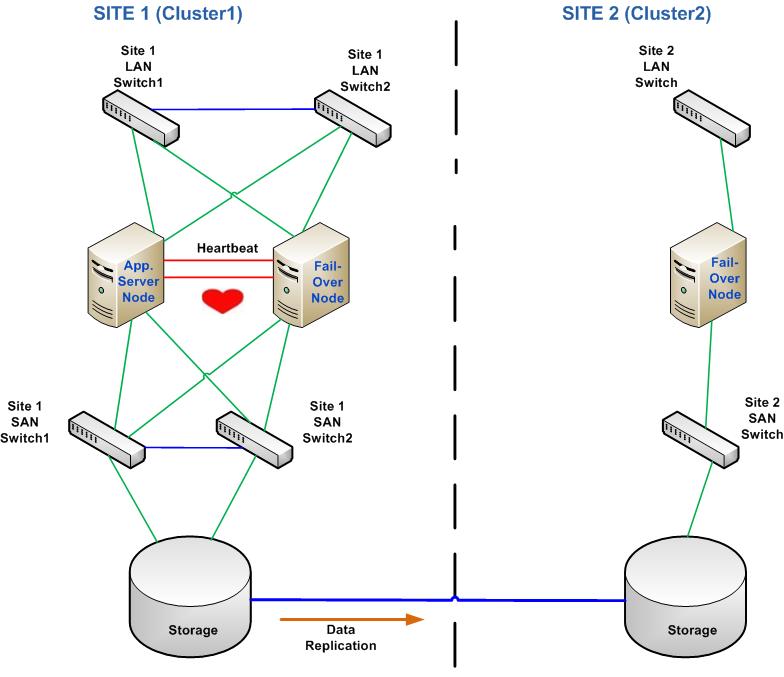
A typical simple High Availability cluster architecture
In this simple High Availability architecture, we have what is called (HA Cluster), “when we have more than one server supporting the same application then the group is called a cluster”. The cluster consists of two boxes (servers), there is a Heartbeat network connection which detects network components failure and help the cutover mechanism which might be a software that provide the ability for the application to be online in the standby node until the main node is back online again, and we also have a storage connected to the servers along with the network connection. If the App in node 1 fails, it will cut over to the node 2. This architecture is called “Local HA” where we have all our nodes in one site.
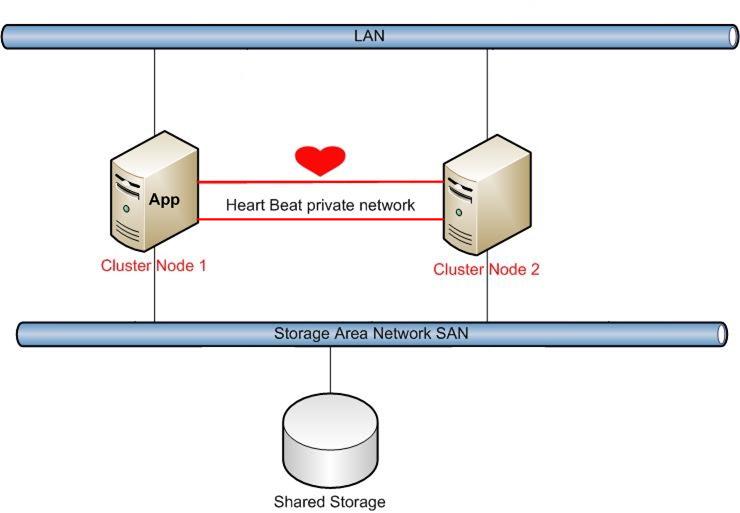
Clustering at campus with more than one cluster site
In case that the business or company is expanding and wanting better Availability, they can employ what is called in-house or “Campus Clustering”. In this scheme as shown, another node is added (Site 2) with the same Heartbeat network through the entire infrastructure, the added node has its own local disk storage but the disk data in Site 2 is a mirror of the data in Site 1, so every storage has dual access so that every node in the entire scheme can see both disk storages.
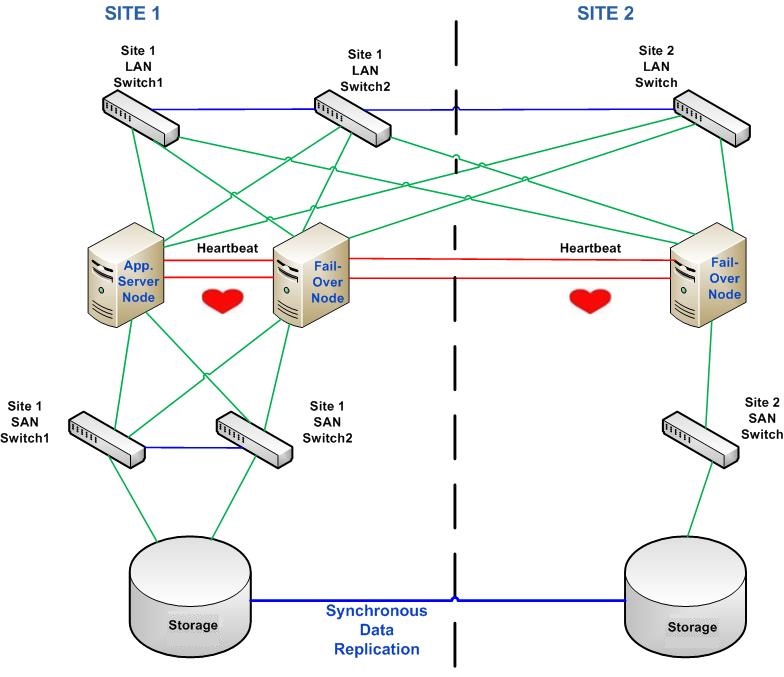
Is mirrored storage practical? The Replicated Data Cluster
In Campus Cluster architecture, we mirrored the storages for Site1 and Site2, this is great solution if we have Site1, and Site2 within relatively short distance, say within the same room, if the distance between storages is large, and latency will data mirroring disruption which in turn will impact the application. The solution is the Replicated Data Cluster RDC, in RDC , instead of mirroring we use keep the connection of each site with its storage disk array and then provide data replication synchronous connection where the application writes its local disk storage and then the storage synchronize the data in standby site’s local storage, replication can be done as in my diagram at the storage level , or at server (host) level, this way the distance between sites could be increased but to apply Replicated Data Clustering, distance still need to be close enough for synchronous connection and in the same local network so RDC is still local HA cluster.
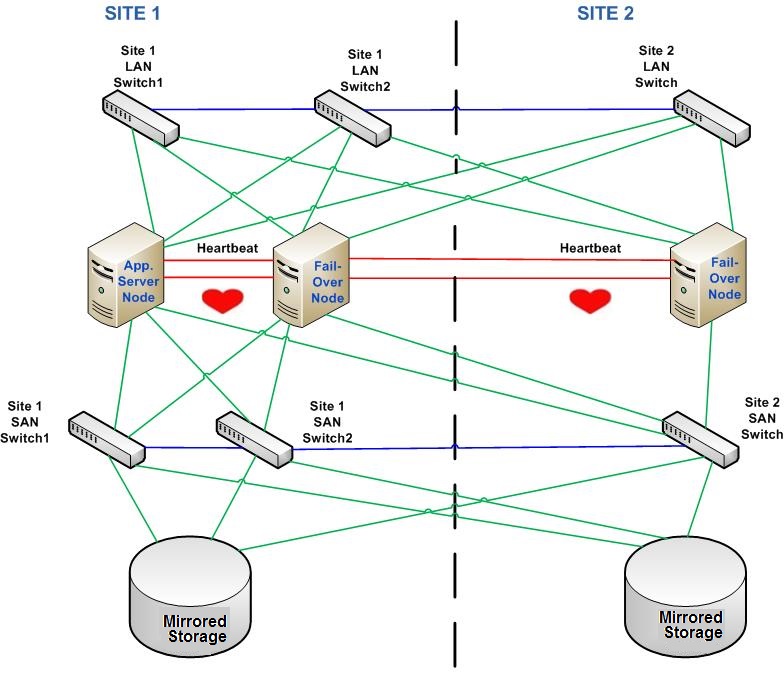
Going big in clustering with Disaster Recovery Architecture
In case that the business is growing and our application start to serve or process huge subscriber data, now it is time to think about what happens if some sort of disaster happened in the business data center such earthquakes, etc. Enters Disaster Recovery Architecture DR. here we have the serving site as a cluster in it is own, and the standby site as it is own cluster so they are not a local High Availability, each cluster can be in a different building, city, or in a different country. In this architecture we still have Data Replication between storage disk arrays, but here the replication is not synchronous because the sites are not close enough, instead data replication is done asynchronously. Here when the Application writes to the local disk storage, it shouldn’t do data replication immediately as in synchronous mode described before, instead it does it when it can.